A couple years ago, I wrote a post entitled Demystifying pi. Since that time, Google Code decided to shut down hosting, so I decided to take a fresh look at it.
Here's a presentation and the new minimal code.
10 June 2015
15 October 2013
Demystifying pi
One of my pet peeves is that we routinely teach kids that things are impossible, unknowable, too complicated, et cetera. Another is when our equations are dirtied with exceptions to rules...
One example of this was my implementation of pi. That in turn was based on a modification of the continued fraction library to be a bit cleaner in the implementation.
It bugged me that my implementation of pi started with an exception. My numerator at index=0 was 22. Something was not quite right - but what was it?
So I thought, well, the number in that position should be 02... but then the continued fraction starts with 0 + 0/ ... That seemed kinda redundant and pointless.
What if we started with index=1? All the sudden, this started to look a lot cleaner... [NOTE: I use 'cf' instead of 'K' to note the indexes are based on the above mentioned modification, not on Gauss's indexes]:
 Ok... this is looking really clean... left side is the odd numbers... right side is the squares (or more specifically, the sum of the odd numbers up to and including the one on the left)... no exceptions to the rule, etc. very clean... but it is no longer pi.
Ok... this is looking really clean... left side is the odd numbers... right side is the squares (or more specifically, the sum of the odd numbers up to and including the one on the left)... no exceptions to the rule, etc. very clean... but it is no longer pi.
π = 4/y.... or more specifically, in this particular case, y = diameter of the circle (⌀) which is about 1.27323954474 (etc)....
What does this mean? It means that π isn't really the important number... ⌀ is. π = 4/⌀, but ⌀ is a very simple continued fraction. π is just derived from it. Maybe if we were teaching how simple continued fractions were, π would not seem like some mystical self-aware number.
Also, to simplify describing these... instead of using LaTeX and such I think we could just specify them as the relationship between two series... For example, ⌀ = A000290::A005408. Similarly, if we wanted to define some 'constant' that was using even numbers instead of odds and the sum of even numbers instead of the sum of odds, we'd have y = A002378::A005843.
UPDATE:
Ok, I admit, the '4' in the definition also bothered me...
Extrapolating further, it appears that this is slightly more correct:
where S = perimeter of a square (ie: the 4 above is the unit square)
where C = circumference of the circle (to find)
then C = S/⌀
aka, while a 1x1 square will mean C=4/⌀; a 3x3 square will mean C=9/⌀
UPDATE:
Obviously, I have to assume that this number has already been defined. It's used everywhere. A quick Google search found nothing until I started trimming the number down. Eventually, I found a reference in The royal gauger; or, gauging made perfectly easy, as it is actually practised by the officers of His Majesty's revenue of excise. In two parts. by Charles Leadbetter. He appears to have referred to it both as "Square of the Diameter of a Circle, whose Area is Unity" as well as "The Multiplier or Multiplicator for reducing a Square to a Circle". He showed how to use it for calculating how much Ale was in a round cask, for example. For reference:




One example of this was my implementation of pi. That in turn was based on a modification of the continued fraction library to be a bit cleaner in the implementation.
It bugged me that my implementation of pi started with an exception. My numerator at index=0 was 22. Something was not quite right - but what was it?
So I thought, well, the number in that position should be 02... but then the continued fraction starts with 0 + 0/ ... That seemed kinda redundant and pointless.
What if we started with index=1? All the sudden, this started to look a lot cleaner... [NOTE: I use 'cf' instead of 'K' to note the indexes are based on the above mentioned modification, not on Gauss's indexes]:

π = 4/y.... or more specifically, in this particular case, y = diameter of the circle (⌀) which is about 1.27323954474 (etc)....
What does this mean? It means that π isn't really the important number... ⌀ is. π = 4/⌀, but ⌀ is a very simple continued fraction. π is just derived from it. Maybe if we were teaching how simple continued fractions were, π would not seem like some mystical self-aware number.
Also, to simplify describing these... instead of using LaTeX and such I think we could just specify them as the relationship between two series... For example, ⌀ = A000290::A005408. Similarly, if we wanted to define some 'constant' that was using even numbers instead of odds and the sum of even numbers instead of the sum of odds, we'd have y = A002378::A005843.
UPDATE:
Ok, I admit, the '4' in the definition also bothered me...
Extrapolating further, it appears that this is slightly more correct:
where S = perimeter of a square (ie: the 4 above is the unit square)
where C = circumference of the circle (to find)
then C = S/⌀
aka, while a 1x1 square will mean C=4/⌀; a 3x3 square will mean C=9/⌀
UPDATE:
Obviously, I have to assume that this number has already been defined. It's used everywhere. A quick Google search found nothing until I started trimming the number down. Eventually, I found a reference in The royal gauger; or, gauging made perfectly easy, as it is actually practised by the officers of His Majesty's revenue of excise. In two parts. by Charles Leadbetter. He appears to have referred to it both as "Square of the Diameter of a Circle, whose Area is Unity" as well as "The Multiplier or Multiplicator for reducing a Square to a Circle". He showed how to use it for calculating how much Ale was in a round cask, for example. For reference:
09 April 2013
A224502: Prime numbers (together with one) whose representation in balanced ternary are palindromes.
Quite often when I am doing prime number research and/or looking for patterns, I check the various number sequences against OEIS to see what other algorithms would come up with the same sequence. Usually, every sequence I look for is in there. For example:
A005408 - Odd Numbers
A000010 - Totients
A007318 - Pascal's Triange
And, now that I have published my first sequence to OEIS:
A224502 - Prime numbers that are Palindromes in Balanced Ternary Notation
For example:
For n=5, a(5)=61 and in balanced ternary notation is 1ī1ī1.
A005408 - Odd Numbers
A000010 - Totients
A007318 - Pascal's Triange
And, now that I have published my first sequence to OEIS:
A224502 - Prime numbers that are Palindromes in Balanced Ternary Notation
For example:
For n=5, a(5)=61 and in balanced ternary notation is 1ī1ī1.
02 November 2011
Shor, I’ll do it
I ran into this article by Scott Aaronson today and thought I would share it. To wet your taste, here's the first sentence of the second paragraph:
Alright, so let’s say you want to break the RSA cryptosystem, in order to rob some banks, read your ex’s email, whatever.Overall, I found it to be a pretty good writeup for the layman. It's a little esoteric when it comes to explaining the QFT, but still - he did a good job.
13 March 2010
Stern–Brocot tree and Continuous Fractions
This post continues the previous entries on Continuous Fractions. This time, we expand the concept to encompass the Stern-Brocot tree.
 The Stern-Brocot tree is a binary search tree where the two legs represent "less than" and "more than" (or Low,High or Left,Right, etc).
The Stern-Brocot tree is a binary search tree where the two legs represent "less than" and "more than" (or Low,High or Left,Right, etc).
As you can see from the image, it starts with 1 (or 1/1) at the top. The left side is less than 1 and the right side is more than 1. Once you choose a side; its' children are then less/more than that node.
Ok, that looks cool -- but what can we do with it?
We can use it to make a simple continued fraction for any positive number (decimal, fraction or whole number). We could probably expand it to handle negative numbers by starting at 0 instead of 1, but then we'd have to revisit the division-by-zero post.

The simple continued fraction is simply the continued fraction that has a '1' for all the partial numerators. Let's look at a simple example of how we can convert a decimal number into a continued fraction through use of the Stern-Brocot tree.
For this example, let's start with a simple decimal... Let's say, 1.25.
To convert the decimal to the SB tree, we'll walk down the tree and record our chosen path with 'L' for left and 'R' for right.
We start with the 1/1. Since 1.25 > 1/1, we choose the Right side of the tree.
Next choice: Since 1.25 < 2/1, we choose the Left path.
Next, 1.25 < 3/2, so again we choose the Left path.
Next, we chose Left for 1.25 < 4/3.
Last, we choose Left for 1.25 = 5/4 and we are done.
So, in order, we chose RLLLL.
We could also write that we chose R1L4.
But how do we translate that to a continued fraction? We just use the exponents!
 R1L4 becomes [1;4].
R1L4 becomes [1;4].
Note: If we were using a number lower than 1 as our target, we'd put a '0' in front of that (like [0;1,4] which is actually the inverse; or 4/5).
The process is easily reversible as well. Let's say we started with that Continued Fraction of [1;4].
First, we need to know whether to start with Left or Right. If the first digit is 0, choose Left; otherwise choose Right. So, for [1;4] we choose Right.
We remember that the number are the exponents; and that it will always alternate. So [1;4] becomes R1L4 .
The exponents represent a count of how many of that letter to choose; so that becomes [R][LLLL] or RLLLL.
Walking down the SB tree, we choose in order: 1/1, 2/1, 3/2, 4/3, 5/4.
Ok, that is all well and good... but that tree only shows a few rows; what do we do when it runs out?
The process for generating the next row isn't so bad when you see it paired with the continued fractions.
Below 5/4 for example:
5/4 = [1;4]
assuming that is in the form [a0;a1,a2,...,ak] the two children are:
[a0;a1,a2,...,ak+1] on the left and [a0;a1,a2,....,ak-1,2] on the right
Or in our particular case:
[1;4+1] = [1;5] = 6/5 = 1.2 on the left
[1;4-1,2] = [1;3,2] = 9/7 = 1.2857142857142858 on the right
and it is easy to verify that 1.2 < 1.25 < 1.2857...
or that 6/5 < 5/4 < 9/7
One more simple example in honor of 1:59 tomorrow....:
RRRLLLLLLLRRRRRRRRRRRRRRRLRRRRRRRRRRRRRRRRRRRRRRRRRLRRRRRRRLLLL
[3;7,15,1,25,1,7,4]
314159/100000 = 3.14159
As you can see from the image, it starts with 1 (or 1/1) at the top. The left side is less than 1 and the right side is more than 1. Once you choose a side; its' children are then less/more than that node.
Ok, that looks cool -- but what can we do with it?
We can use it to make a simple continued fraction for any positive number (decimal, fraction or whole number). We could probably expand it to handle negative numbers by starting at 0 instead of 1, but then we'd have to revisit the division-by-zero post.
The simple continued fraction is simply the continued fraction that has a '1' for all the partial numerators. Let's look at a simple example of how we can convert a decimal number into a continued fraction through use of the Stern-Brocot tree.
For this example, let's start with a simple decimal... Let's say, 1.25.
To convert the decimal to the SB tree, we'll walk down the tree and record our chosen path with 'L' for left and 'R' for right.
We start with the 1/1. Since 1.25 > 1/1, we choose the Right side of the tree.
Next choice: Since 1.25 < 2/1, we choose the Left path.
Next, 1.25 < 3/2, so again we choose the Left path.
Next, we chose Left for 1.25 < 4/3.
Last, we choose Left for 1.25 = 5/4 and we are done.
So, in order, we chose RLLLL.
We could also write that we chose R1L4.
But how do we translate that to a continued fraction? We just use the exponents!

Note: If we were using a number lower than 1 as our target, we'd put a '0' in front of that (like [0;1,4] which is actually the inverse; or 4/5).
The process is easily reversible as well. Let's say we started with that Continued Fraction of [1;4].
First, we need to know whether to start with Left or Right. If the first digit is 0, choose Left; otherwise choose Right. So, for [1;4] we choose Right.
We remember that the number are the exponents; and that it will always alternate. So [1;4] becomes R1L4 .
The exponents represent a count of how many of that letter to choose; so that becomes [R][LLLL] or RLLLL.
Walking down the SB tree, we choose in order: 1/1, 2/1, 3/2, 4/3, 5/4.
Ok, that is all well and good... but that tree only shows a few rows; what do we do when it runs out?
The process for generating the next row isn't so bad when you see it paired with the continued fractions.
Below 5/4 for example:
5/4 = [1;4]
assuming that is in the form [a0;a1,a2,...,ak] the two children are:
[a0;a1,a2,...,ak+1] on the left and [a0;a1,a2,....,ak-1,2] on the right
Or in our particular case:
[1;4+1] = [1;5] = 6/5 = 1.2 on the left
[1;4-1,2] = [1;3,2] = 9/7 = 1.2857142857142858 on the right
and it is easy to verify that 1.2 < 1.25 < 1.2857...
or that 6/5 < 5/4 < 9/7
One more simple example in honor of 1:59 tomorrow....:
RRRLLLLLLLRRRRRRRRRRRRRRRLRRRRRRRRRRRRRRRRRRRRRRRRRLRRRRRRRLLLL
[3;7,15,1,25,1,7,4]
314159/100000 = 3.14159
16 June 2009
Slashdot: 47th Mersenne Prime Confirmed
The new prime, 2^42,643,801 - 1, is actually smaller than the one discovered previously.
18 May 2009
Primality of 1
When I was in school, I remember them teaching that a prime number was any number divisible by only 1 and itself. Thus, in school, they taught that 1 was prime. Since then, I have noticed that everyone insists that 1 is not prime. Since many of the patterns I find work better with 1 being prime, I decided to try to figure out why the discrepancy...
From Wikipedia:
I know, I know... soapbox, right? First the divide-by-zero post, then this... How about this, as soon as we can explain all our math in simple fractals without saying things like "except 0 or 1" or "with n>1", then I'll change my position on it.
From Wikipedia:
Until the 19th century, most mathematicians considered the number 1 a prime, with the definition being just that a prime is divisible only by 1 and itself but not requiring a specific number of distinct divisors. There is still a large body of mathematical work that is valid despite labelling 1 a prime, such as the work of Stern and Zeisel. Derrick Norman Lehmer's list of primes up to 10,006,721, reprinted as late as 1956,[2] started with 1 as its first prime.[3] Henri Lebesgue is said to be the last professional mathematician to call 1 prime.[citation needed] The change in label occurred so that the fundamental theorem of arithmetic, as stated, is valid, i.e., “each number has a unique factorization into primes.”[4][5]So there you have it. They decided in the last 43 years that 1 could no longer be prime so that one of their theorems could be correct. Why does that remind me of someone fudging statistics?
I know, I know... soapbox, right? First the divide-by-zero post, then this... How about this, as soon as we can explain all our math in simple fractals without saying things like "except 0 or 1" or "with n>1", then I'll change my position on it.
Thus Theorem 1 of Hardy & Wright (1979) takes the form, “Every positive integer, except 1, is a product of primes”bah humbug ;)
17 May 2009
Prime digits
A coworker made a comment to me Friday about the distribution of digits in prime numbers. He was referring to a recent Slashdot article talking about the first digit in the prime number...
but I have never liked thinking of the 1st digit as the far left... I'd prefer to think of the far right digit as digit 0. Can't help it - it's the whole positional notation thing (10^3 10^2 10^1 10^0 . 10^-1 10^-2 etc)...
So I started looking at the distribution of the primes on the right side.
The last digit (digit 0, far right digit) is directly related to the number of primes...
Now 2 and 5 are both used once (for themselves).
0,4,6 and 8 are never used.
1,3,7,9 all follow this pattern:
Assume {x} = {1,3,7,9}
Assume {y} = {all primes < 10^n}
let z = ({y} ≡ x (mod 10^n))
z is also the number of times that x was the last digit in {y}
So let's look at a simple example...
{y} = {all primes < 10000}
0 was never the last digit
1 was the last digit 307 times (if you count 1 as prime, 306 otherwise)
2 was the last digit once ('2')
3 was the last digit 310 times
4 was never the last digit
5 was the last digit once ('5')
6 was never the last digit
7 was the last digit 308 times
8 was never the last digit
9 was the last digit 303 times
similarly...
there were 307 primes ≡ 1 (mod 10000) [assuming 1 counts as prime]
there was 310 primes ≡ 3 (mod 10000)
there was 308 primes ≡ 7 (mod 10000)
there was 303 primes ≡ 9 (mod 10000)
For {y} < 100000, we have
0 2388 1 2402 0 1 0 2411 0 2390
For {y} < 1000000, we have
0 19618 1 19665 0 1 0 19621 0 19593
etc
Checking OEIS, I found those sequences listed here:
A073505 for 1 (if 1 is *NOT* prime)
A073506 for 3
A073507 for 7
A073509 for 9
A006880 seems to be the SUM of each line
Example: 0+307+1+310+0+1+0+308+0+303=1230 [-1 for the sequence due to 1 being prime or not] < 10^4
So it doesn't really get us much... but it does tell us that the number of primes ending in X is equal to the number of primes congruent to X mod 10^n.
but I have never liked thinking of the 1st digit as the far left... I'd prefer to think of the far right digit as digit 0. Can't help it - it's the whole positional notation thing (10^3 10^2 10^1 10^0 . 10^-1 10^-2 etc)...
So I started looking at the distribution of the primes on the right side.
The last digit (digit 0, far right digit) is directly related to the number of primes...
Now 2 and 5 are both used once (for themselves).
0,4,6 and 8 are never used.
1,3,7,9 all follow this pattern:
Assume {x} = {1,3,7,9}
Assume {y} = {all primes < 10^n}
let z = ({y} ≡ x (mod 10^n))
z is also the number of times that x was the last digit in {y}
So let's look at a simple example...
{y} = {all primes < 10000}
0 was never the last digit
1 was the last digit 307 times (if you count 1 as prime, 306 otherwise)
2 was the last digit once ('2')
3 was the last digit 310 times
4 was never the last digit
5 was the last digit once ('5')
6 was never the last digit
7 was the last digit 308 times
8 was never the last digit
9 was the last digit 303 times
similarly...
there were 307 primes ≡ 1 (mod 10000) [assuming 1 counts as prime]
there was 310 primes ≡ 3 (mod 10000)
there was 308 primes ≡ 7 (mod 10000)
there was 303 primes ≡ 9 (mod 10000)
For {y} < 100000, we have
0 2388 1 2402 0 1 0 2411 0 2390
For {y} < 1000000, we have
0 19618 1 19665 0 1 0 19621 0 19593
etc
Checking OEIS, I found those sequences listed here:
A073505 for 1 (if 1 is *NOT* prime)
A073506 for 3
A073507 for 7
A073509 for 9
A006880 seems to be the SUM of each line
Example: 0+307+1+310+0+1+0+308+0+303=1230 [-1 for the sequence due to 1 being prime or not] < 10^4
So it doesn't really get us much... but it does tell us that the number of primes ending in X is equal to the number of primes congruent to X mod 10^n.
27 April 2009
Division by Zero
I've been on this kick lately where I have started question some of the basic assumptions I learned in math... things like "you can't easily define pi" or the concept of an "irrational number". Today's philosophical debate is on the idea of division by zero.
This came up because I was creating a ContinuedFraction interface for integers... The number 3, for instance, is 3 + 0/0 + 0/0 .... etc... instead of zeros I had to replace them with nulls in order to prevent the app from trying to compute the 0/0 bit... That got me thinking... maybe it should be allowed...
Let's take a simple concept. Let's say there are 10 pennies on the table, and it is decided that the pennies will be split evenly amongst everyone at the table. [Yes, pennies - I don't want anyone getting the bright idea to make change].
Now, if there are 5 people, everyone gets 2 pennies. Simple.
If there are 3 people, everyone gets 3 pennies and 1 is left on the table.
If there are no people, then there is still 10 pennies on the table.
What's so difficult about that?
So, in essence:
10/5 = 2r0
10/3 = 3r1
10/0 = 0r10
Seems like Occams Razor would say that the whole concept has been arbitrarily inflated to give us errors, exceptions and NaN.
What about the other way around?
If there are 0 pennies...
0/5 = no pennies for anyone
0/3 = same
0/0 = same
Seems like we really don't have an issue there.
Of course, this would mean that things such as limits get screwed up -- but so what. If we think we have irrational numbers, why not stir the pot a bit? Maybe they were not correctly defined in the first place.
Besides, that will open up the ContinuedFractions to more interesting options... like

This came up because I was creating a ContinuedFraction interface for integers... The number 3, for instance, is 3 + 0/0 + 0/0 .... etc... instead of zeros I had to replace them with nulls in order to prevent the app from trying to compute the 0/0 bit... That got me thinking... maybe it should be allowed...
Let's take a simple concept. Let's say there are 10 pennies on the table, and it is decided that the pennies will be split evenly amongst everyone at the table. [Yes, pennies - I don't want anyone getting the bright idea to make change].
Now, if there are 5 people, everyone gets 2 pennies. Simple.
If there are 3 people, everyone gets 3 pennies and 1 is left on the table.
If there are no people, then there is still 10 pennies on the table.
What's so difficult about that?
So, in essence:
10/5 = 2r0
10/3 = 3r1
10/0 = 0r10
Seems like Occams Razor would say that the whole concept has been arbitrarily inflated to give us errors, exceptions and NaN.
What about the other way around?
If there are 0 pennies...
0/5 = no pennies for anyone
0/3 = same
0/0 = same
Seems like we really don't have an issue there.
Of course, this would mean that things such as limits get screwed up -- but so what. If we think we have irrational numbers, why not stir the pot a bit? Maybe they were not correctly defined in the first place.
Besides, that will open up the ContinuedFractions to more interesting options... like

26 April 2009
SeriesCF
While working on my ContinuedFractions library today, it occured to me that our current representation of pi could be simplified by just specifying the numerators and denominators as series...
I went ahead and changed the implementation to use a new SeriesCF class instead of the default ContinuedFraction class and I think the new approach is much cleaner.

25 April 2009
PresenTeX
While writing this package today, I came across the PresenTeX website. Very nice...
from

from
cf = d_0 + \cfrac{n_0}{d_1 + \cfrac{n_1}{d_2 + \cfrac{n_2}{d_3 + \cfrac{n_3}{\ddots\,}}}}

10 February 2009
Continued Fractions


I was working on some continued fractions, and came across the fundamental recurrence formula above. It worked pretty well for some simple continued fractions (like √2) but seemed to be a bit unfriendly towards calculating π.
I'm using this definition of π:
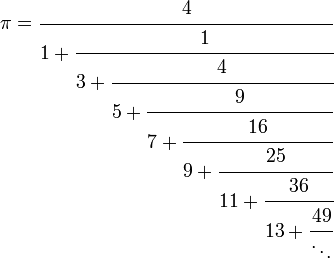
Now, using that definition with the above equation, it was always completely wrong...
So I tried changing the equation...
I'm using this definition of π:
Now, using that definition with the above equation, it was always completely wrong...
So I tried changing the equation...
 So you'll notice a few specific changes... 1) A1 has been redefined in terms of previous results. 2) A1 reduced the index on a1 to a0. 3) An+1 changed the index on an+1 to an. 4) Bn+1 changed the index on bn+1 to bn.
So you'll notice a few specific changes... 1) A1 has been redefined in terms of previous results. 2) A1 reduced the index on a1 to a0. 3) An+1 changed the index on an+1 to an. 4) Bn+1 changed the index on bn+1 to bn.This may seem like a lot of changes, but really #1 didn't change the outcome at all and the rest were all about reducing the index of a/b.
Net result? All the previous stuff (√2, golden mean, etc) give the same results as before... but now π works.
27 July 2007
Intuitive Approach to Wilson's Theorem
The other day I stumbled across something, only later to realize that it was Wilson's Theorem. Since the approach used to find it in the first place was more of a 'common-sense' approach than what you usually encounter for it, I thought I would go ahead and present it.
Let's look at two examples.... For both, what we are looking for is:
(n-1)! % n ≡ (n-1) mod n; iff n is prime
Example 1: Composite Numbers
Let's try to determine whether '10' is prime (which we know it isn't but that just makes the example easier to follow)...
(n-1)! is 1*2*3*4*5*6*7*8*9
when we mod it by 10, what we are really saying is to "find missing factors of 10"
since both 2 and 5 are in the list, the end result will be 0*
ie: (10-1)! % 10 ≡ 0 mod 10
Example 2: Prime Numbers
Let's try to determine whether '11' is prime
(n-1)! is 1*2*3*4*5*6*7*8*9*10
when we mod by 11, what we are really saying is to "find missing factors of 11"
since 11 is not in the list, the number is prime and the end result is 10 (or -1)
ie: (11-1)! % 11 ≡ 10 mod 11
or: (11-1)! % 11 ≡ -1 mod 11
* It appears that the only composite number to NOT result into congruency with 0 is '4'
(4-1)! % 4 ≡ 2 mod 4
I believe this is because it is 2-squared and it 2-away from it... thus since we get further away as we go on, it won't happen again.
Unfortunately, this didn't end up being nearly as clear as my first draft did, but let's try to make the useful bit clear here... directly from Wilson's theorem:
(n-1)! % n ≡ -1 mod n; iff n is prime
or
(n-1)! % n = (n-1) mod n; iff n is prime
or... to put it into Windows Calculator speak:
[type in some number][M+][-][1][=][n!][mod][MR][=]
if the result is equal to [MR]-1 then it is prime
otherwise the result will be 0 (or '2' for n=4) and the number is composite/non-prime
Let's look at two examples.... For both, what we are looking for is:
(n-1)! % n ≡ (n-1) mod n; iff n is prime
Example 1: Composite Numbers
Let's try to determine whether '10' is prime (which we know it isn't but that just makes the example easier to follow)...
(n-1)! is 1*2*3*4*5*6*7*8*9
when we mod it by 10, what we are really saying is to "find missing factors of 10"
since both 2 and 5 are in the list, the end result will be 0*
ie: (10-1)! % 10 ≡ 0 mod 10
Example 2: Prime Numbers
Let's try to determine whether '11' is prime
(n-1)! is 1*2*3*4*5*6*7*8*9*10
when we mod by 11, what we are really saying is to "find missing factors of 11"
since 11 is not in the list, the number is prime and the end result is 10 (or -1)
ie: (11-1)! % 11 ≡ 10 mod 11
or: (11-1)! % 11 ≡ -1 mod 11
* It appears that the only composite number to NOT result into congruency with 0 is '4'
(4-1)! % 4 ≡ 2 mod 4
I believe this is because it is 2-squared and it 2-away from it... thus since we get further away as we go on, it won't happen again.
Unfortunately, this didn't end up being nearly as clear as my first draft did, but let's try to make the useful bit clear here... directly from Wilson's theorem:
(n-1)! % n ≡ -1 mod n; iff n is prime
or
(n-1)! % n = (n-1) mod n; iff n is prime
or... to put it into Windows Calculator speak:
[type in some number][M+][-][1][=][n!][mod][MR][=]
if the result is equal to [MR]-1 then it is prime
otherwise the result will be 0 (or '2' for n=4) and the number is composite/non-prime
Subscribe to:
Posts (Atom)